NPU 系统介绍
V853 芯片内置一颗 NPU,其处理性能为最大 1 TOPS 并有 128KB 内部高速缓存用于高速数据交换,支持 VIPLite 调用接口,并支持导入大量常用的深度学习模型进行运算,同时支持常用的深度学习框架导入,例如 TensorFlow,Caffe,TFLite,Keras,Pytorch,Onnx等
NPU 系统架构
NPU 的系统架构如下图所示:
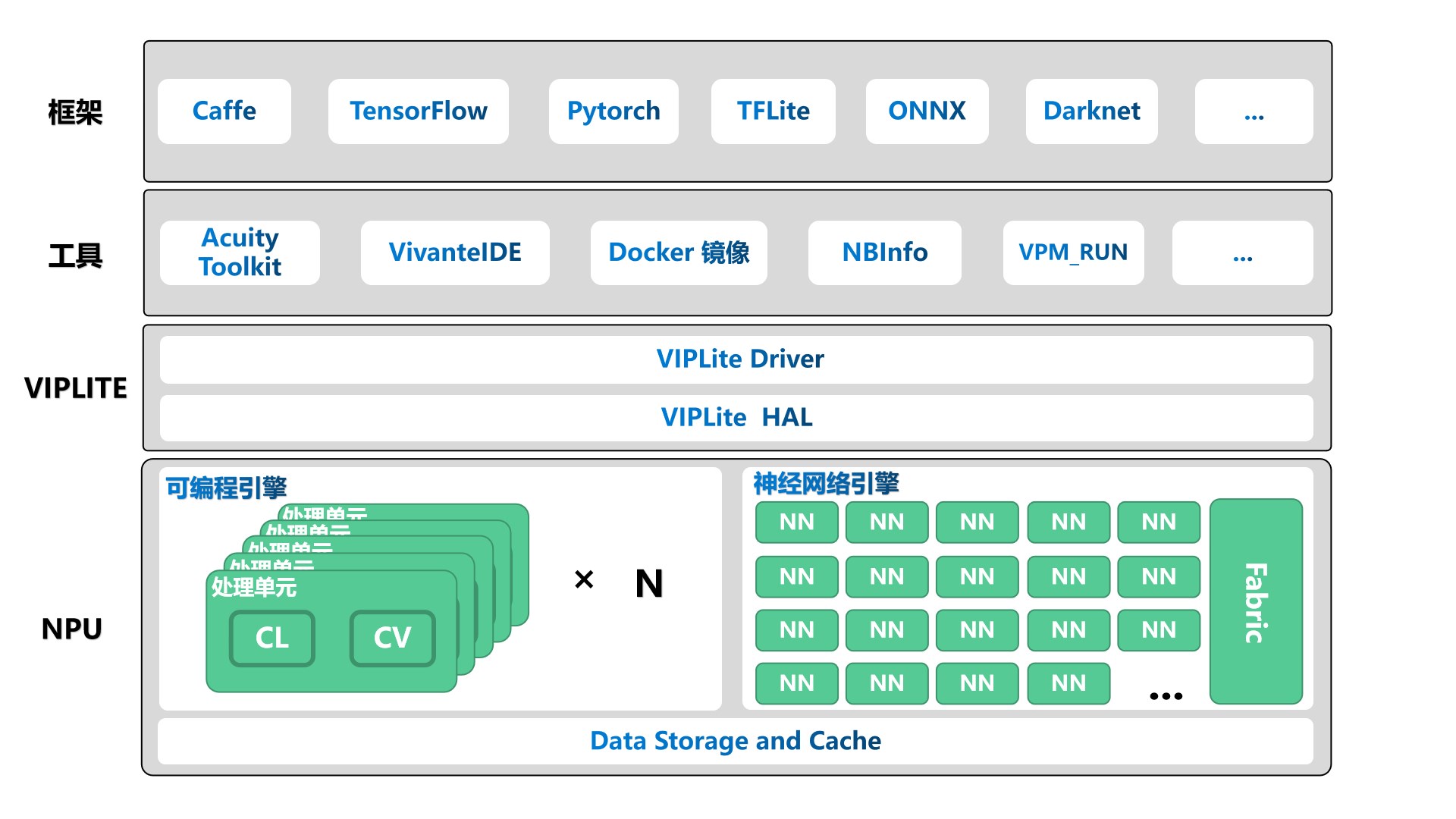
上层的应用程序可以通过加载模型与数据到 NPU 进行计算,也可以使用 NPU 提供的软件 API 操作 NPU 执行计算。
NPU包括三个部分:可编程引擎(Programmable Engines,PPU)、神经网络引擎(Neural Network Engine,NN)和各级缓存。
可编程引擎可以使用 EVIS 硬件加速指令与 Shader 语言进行编程,也可以实现激活函数等操作。
神经网络引擎包含 NN 核心与 Tensor Process Fabric(TPF,图中简写为 Fabric) 两个部分。NN核心一般计算卷积操作, Tensor Process Fabric 则是作为 NN 核心中的高速数据交换的通路。算子是由可编程引擎与神经网络引擎共同实现的。
NPU 支持 UINT8,INT8,INT16 三种数据格式。
NPU 模型转换
NPU 使用的模型是 NPU 自定义的一类模型结构,不能直接将网络训练出的模型直接导入 NPU 进行计算。这就需要将网络训练出的转换模型到 NPU 的模型上。
NPU 的模型转换步骤如下图所示:
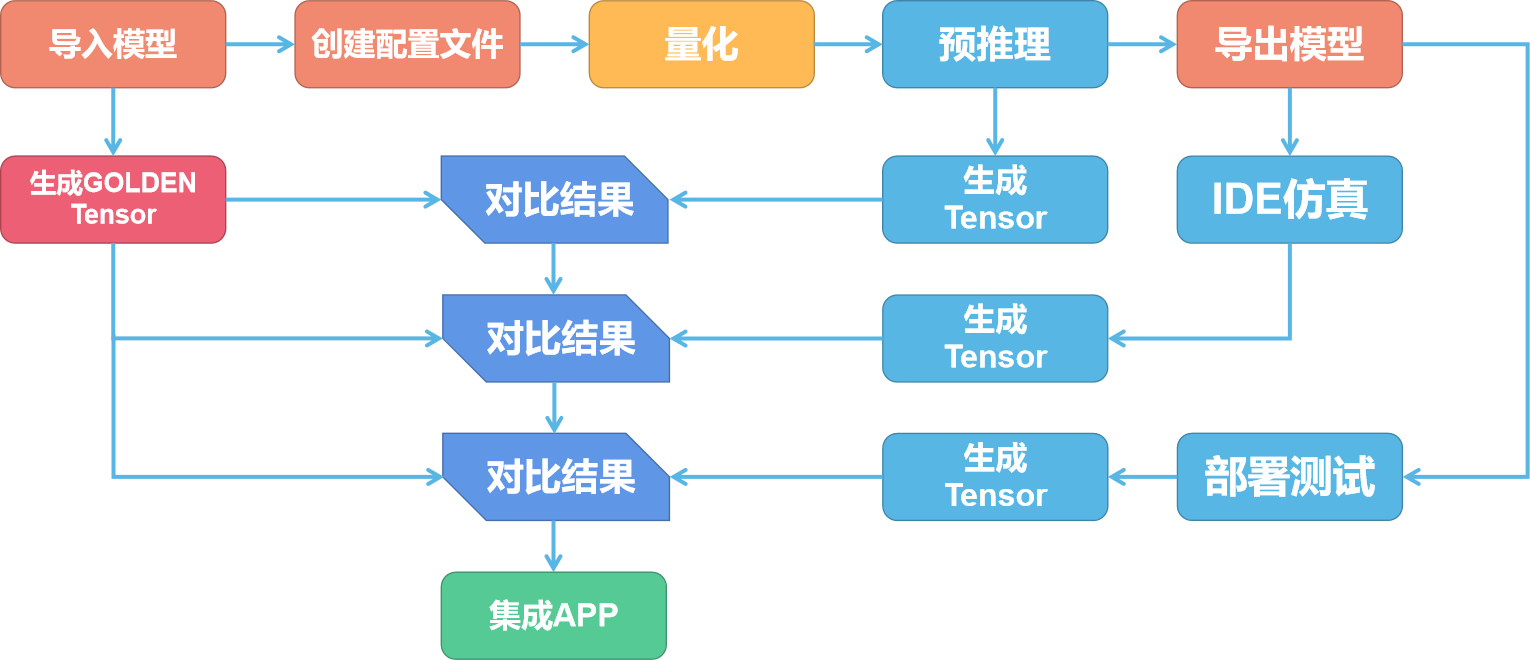
NPU 模型转换包括准备阶段、量化阶段与验证阶段。
准备阶段
首先我们把准备好模型使用工具导入,并创建配置文件。
这时候工具会把模型导入并转换为 NPU 所使用的网络模型、权重模型与配置文件。
配置文件用于对网络的输入和输出的参数进行描述以及配置。这些参数包括输入/输出 tensor 的形状、归一化系数 (均值/零点)、图像格式、tensor 的输出格式、后处理方式等等。
量化阶段
由于训练好的神经网络对数据精度以及噪声的不敏感,因此可以通过量化将参数从浮点数转换为定点数。这样做有两个优点:
(1)减少了数据量,进而可以使用容量更小的存储设备,节省了成本;
(2)由于数据量减少,浮点转化为定点数也大大降低了系统的计算量,也提高了计算的速度。
但是量化也有一个致命缺陷——会导致精度的丢失。
由于浮点数转换为定点数时会大大降低数据量,导致实际的权重参数准确度降低。在简单的网络里这不是什么大问题,但是如果是复杂的多层多模型的网络,每一层微小的误差都会导致最终数据的错误。
那么,可以不量化直接使用原来的数据吗?当然是可以的。
但是由于使用的是浮点数,无法将数据导入到只支持定点运算的 NN 核心进行计算,这就需要可编程引擎来代替 NN 核进行计算,这样可以大大降低运算效率。
另外,在进行量化过程时,不仅对参数进行了量化,也会对输入输出的数据进行量化。如果模型没有输入数据,就不知道输入输出的数据范围。这时候我们就需要准备一些具有代表性的输入来参与量化。这些输入数据一般从训练模型的数据集里获得,例如图片数据集里的图片。
另外选择的数据集不一定要把所有训练数据全部加入量化,通常我们选择几百张能够代表所有场景的输入数据就即可。理论上说,量化数据放入得越多,量化后精度可能更好,但是到达一定阈值后效果增长将会非常缓慢甚至不再增长。
这里是一个因为错误的量化导致精度丢失并识别失败的案例:

而正常情况应该是这样的:

验证阶段
由于上一阶段对模型进行了量化导致了精度的丢失,就需要对每个阶段的模型进行验证,对比结果是否一致。
首先我们需要使用非量化情况下的模型运行生成每一层的 tensor 作为 Golden tensor。输入的数据可以是数据集中的任意一个数据。然后量化后使用预推理相同的数据再次输出一次 tensor,对比这一次输出的每一层的 tensor 与 Golden tensor 的差别。
如果差别较大可以尝试更换量化模型和量化方式。差别不大即可使用 IDE 进行仿真。也可以直接部署到 V853 上进行测试。
此时测试同样会输出 tensor 数据,对比这一次输出的每一层的 tensor 与 Golden tensor 的差别,差别不大即可集成到 APP 中了。
模型转换实操
NPU 模型的部署
NPU 系统的模型部署流程一般包括以下四个部分:

数据预处理
数据预处理即将数据处理到适合模型使用的过程。
这里就以一个图像主体识别案例来举例:摄像头捕获到了图像数据,其数据格式是YUV的,而我们的模型使用的输入数据是RGB的数据,所以需要使用前处理将 YUV 数据转换到 RGB。
模型部署实操
接下来是将模型加载到 NPU 内,初始化 NPU 的环境与分配内存,然后将之前预处理的数据交给 NPU 进行计算。计算后 NPU 会输出一个 tensor 数据,这时候就需要数据后处理,将 tensor 数据转换为具体的坐标与类型,就可以反馈到上层应用程序做应用的处理了。
部署实操详见:NPU 模型的部署
FAQ
(1)NPU 支持调用算子级别的运算吗?支持哪些算子?
NPU 默认使用的是网络级别的调用,但是 NPU 同时也支持算子级别的调用。不过由于直接调用算子导致数据需要到内存里交换,不能通过 NPU 内置的SRAM交换,大大降低了效率,不推荐这样的做法。
NPU 使用的是双算子结构,其中的神经网络引擎使用的是硬算子,其性能很高,速度很快;而可编程引擎属于软算子,可以覆盖硬件算子没有支持的一些算子结构。硬算子覆盖了大部分的卷积操作。而软算子可以通过编程实现算子。具体的算子支持表格可以到文档《Operation Mapping and Support》查询。
(2)NPU 是否支持 FP16,FP32?
不支持。
(3)NPU 支持多模型运行吗?
支持多模型运行
(4)是否可以使用自己的量化函数量化?
可以的,只需要输出的量化表符合格式即可。
(5)NPU 支持的模型
V853 支持的常用深度学习框架模型有:
- TensorFlow
- Caffe
- TFLite
- Keras
- Pytorch
- Onnx NN
- Darknet
- and so on...